본 번역은 원글을 대상으로 CC-BY 라이선스를 사용하고 있어 마음껏 번역하였습니다.
요약 : {purrr}의map_dfr()함수로 폴더내의 파일 리스트를 한번에 불러올 수 있다.
이번 포스트는 tidyverse 패키지에 속한 두
패키지(purrr&readr)를 사용해서 csv 파일
리스트를 하나의 data.frame으로 불러오는 방법을 설명합니다. 또한
fs라는 새로운 파일 시스템 대응 패키지를 사용합니다.
문제 상황 설정
규칙적인 데이터를 포함하는 CSV 파일들이 한 디렉토리에 있다고 가정합니다. 즉, 각 데이터 세트의 열이 모두 동일하거나 적어도 중복되는 열이 동일하다는 것을 의미한다고 가정합니다.
우리는 디렉토리 안의 모든 CSV 파일을 읽어서 각각의 파일을 불러온 작은 데이터셋을 합쳐 하나의 큰 데이터셋으로 만들고 싶습니다.
예제 데이터
예를 좀 더 구체적으로 설명하기 위해 아일랜드 정부가 제공한 데이터셋을 사용하겠습니다. 이 데이터셋은 병원 부서별 연간 온라인 추천수로, 각 년도별로 파일이 구분되어 있습니다.
데이터는 data.gov.ie에서 개별 csv 파일들을 다운로드 받거나, 미리 준비한 압축 파일을 다운 받을 수 있습니다.
한 폴더 내에 csv 파일들을 다운로드 받았거나, 압축 파일을 풀어놓은
후에 data_dir 객체에 경로를 지정합니다.
data_dir <- "ie-general-referrals-by-hospital"
fs::dir_ls() 함수를 사용해서 폴더내의 파일 리스트를
가져올 수 있습니다.
fs::dir_ls(data_dir)
ie-general-referrals-by-hospital/README.txt
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2015.csv
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2016.csv
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2017.csv
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2018.csv리스트를 보니 README.txt 파일이 추가로 있습니다. 이
파일은 우리가 불러오고자 하는 파일이 아닙니다. 그렇기 때문에 폴더 내의
파일 리스트를 불러올 때 csv 파일 형식으로만 제한할 필요가 있습니다.
파일명이 .csv로 끝나는 것들만 조건을 주면 좋겠습니다.
csv_files <- fs::dir_ls(data_dir, regexp = "\\.csv$")
csv_files
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2015.csv
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2016.csv
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2017.csv
ie-general-referrals-by-hospital/general-referrals-by-hospital-department-2018.csv파일 전체를 불러오기
우선 한 파일을 불러오기
각 csv 파일들을 readr::read_csv() 함수를 이용해서 각각
불러올 수 있습니다. 한 파일만 먼저 예시로 불러와 보겠습니다.
readr::read_csv(csv_files[1])
# A tibble: 837 × 6
Month_Year Hospital_Name Hospital_ID Hospital_Depart… ReferralType
<chr> <chr> <dbl> <chr> <chr>
1 Aug-15 AMNCH 1049 Paediatric ENT General Ref…
2 Aug-15 AMNCH 1049 Paediatric Gast… General Ref…
3 Aug-15 AMNCH 1049 Paediatric Gene… General Ref…
4 Aug-15 Bantry Genera… 704 Gastroenterology General Ref…
5 Aug-15 Bantry Genera… 704 General Medicine General Ref…
6 Aug-15 Bantry Genera… 704 General Surgery General Ref…
7 Aug-15 Bantry Genera… 704 Medicine for th… General Ref…
8 Aug-15 Bantry Genera… 704 Outreach Dermat… General Ref…
9 Aug-15 Bantry Genera… 704 Outreach Orthop… General Ref…
10 Aug-15 Bantry Genera… 704 Outreach Surgic… General Ref…
# … with 827 more rows, and 1 more variable: TotalReferrals <dbl>전체 파일 불러오기로 확장하기
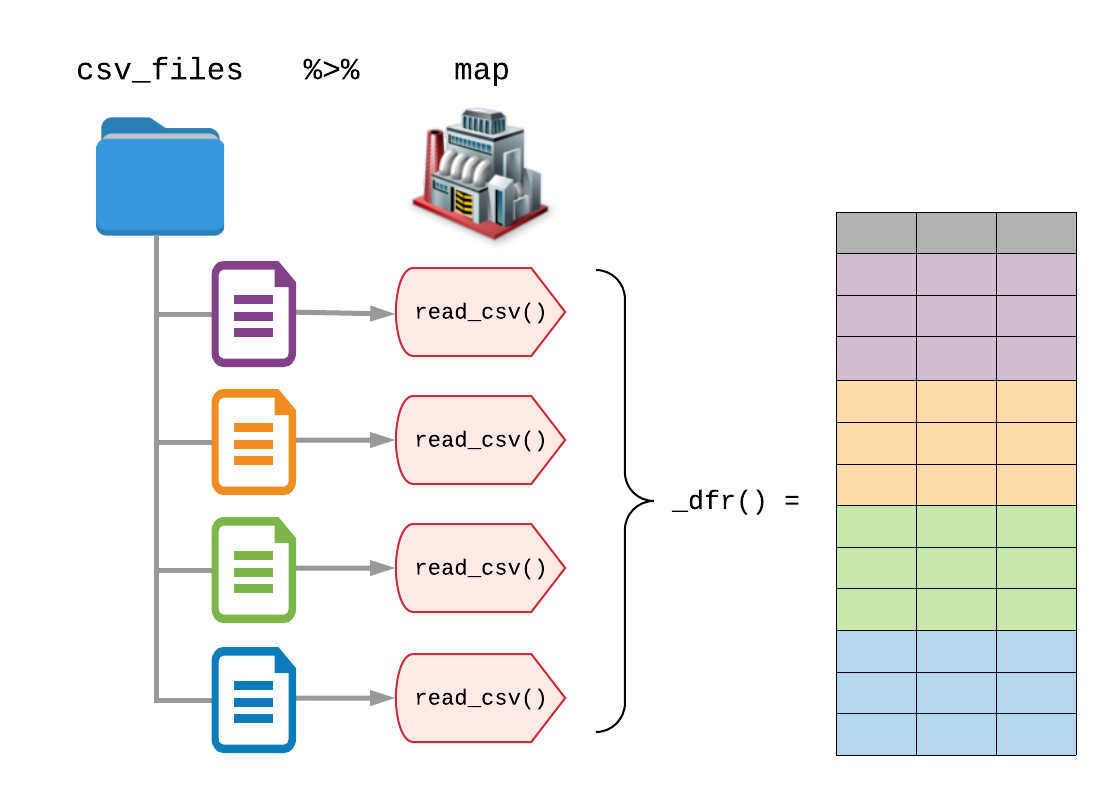
디렉토리의 모든 파일을 읽으려면 purrr::map()을 사용하여
read_csv()를 파일 목록에 매핑(map)합니다.
그러나 각 list() 내의 요소가 tibble(또는 data.frame)이 될 것이고 각
데이터 프레임이 동일한 열을 가짐을 알고 있으니, purrr의 타입 지정 함수인
purrr::map_dfr()를 사용하여 가져온 CSV 파일 각각을 포함하는
단일 data.frame으로 가져와 보겠습니다. *_dfr()가 추가로
달려있는 함수들은 각 요소를 행결합(row-binding)하여 data.frame을
반환하도록 합니다.(이것은 map() %>% bind_rows() 를
호출하는 것과 같습니다.)
# A tibble: 12,278 × 6
Month_Year Hospital_Name Hospital_ID Hospital_Depart… ReferralType
<chr> <chr> <dbl> <chr> <chr>
1 Aug-15 AMNCH 1049 Paediatric ENT General Ref…
2 Aug-15 AMNCH 1049 Paediatric Gast… General Ref…
3 Aug-15 AMNCH 1049 Paediatric Gene… General Ref…
4 Aug-15 Bantry Genera… 704 Gastroenterology General Ref…
5 Aug-15 Bantry Genera… 704 General Medicine General Ref…
6 Aug-15 Bantry Genera… 704 General Surgery General Ref…
7 Aug-15 Bantry Genera… 704 Medicine for th… General Ref…
8 Aug-15 Bantry Genera… 704 Outreach Dermat… General Ref…
9 Aug-15 Bantry Genera… 704 Outreach Orthop… General Ref…
10 Aug-15 Bantry Genera… 704 Outreach Surgic… General Ref…
# … with 12,268 more rows, and 1 more variable: TotalReferrals <dbl>전체 파일을 불러올 때 추가 설정하기
Month_Year 컬럼이 날짜/시간 자료형이 아니라 글자로
불러와져 있는 것을 알 수 있습니다. read_csv() 함수의 인자를
read_csv()함수에서 사용하는 것 처럼 map_dfr()
안에서 사용할 수 있습니다.(역자 주: read_csv() 함수에서
컬럼의 자료형을 지정하는 형태의 인자를 뜻합니다. 개인적으로는 다음
방법인 불러온 후 수정하는 방식을 선호합니다.)
# A tibble: 12,278 × 6
Month_Year Hospital_Name Hospital_ID Hospital_Depart… ReferralType
<date> <chr> <dbl> <chr> <chr>
1 2015-08-01 AMNCH 1049 Paediatric ENT General Ref…
2 2015-08-01 AMNCH 1049 Paediatric Gast… General Ref…
3 2015-08-01 AMNCH 1049 Paediatric Gene… General Ref…
4 2015-08-01 Bantry Genera… 704 Gastroenterology General Ref…
5 2015-08-01 Bantry Genera… 704 General Medicine General Ref…
6 2015-08-01 Bantry Genera… 704 General Surgery General Ref…
7 2015-08-01 Bantry Genera… 704 Medicine for th… General Ref…
8 2015-08-01 Bantry Genera… 704 Outreach Dermat… General Ref…
9 2015-08-01 Bantry Genera… 704 Outreach Orthop… General Ref…
10 2015-08-01 Bantry Genera… 704 Outreach Surgic… General Ref…
# … with 12,268 more rows, and 1 more variable: TotalReferrals <dbl>날짜 자료형 문제를 불러오기 이후에 처리하기
read_csv() 함수의 인자를 설정하면, 대부분의 파일에서 잘
동작합니다. 하지만, 2016년에 Month_Year의 양식이
Jan-15에서 Jan-2016로 바뀌어서 2016년과 2017년
데이터가 NA로 불러와지고 말았습니다.
이것을 고치는 가장 쉬운 방법은, 글자 자료형 그대로 불러온 후에
lubridate 패키지의 날짜 변환 함수를 사용하는 것입니다.
readr의 col_date() 함수는 하나의 포멧만 허용하기 때문입니다.
library(lubridate)
csv_files %>%
map_dfr(read_csv) %>%
mutate(Month_Year = myd(Month_Year, truncated = 1))
# A tibble: 12,278 × 6
Month_Year Hospital_Name Hospital_ID Hospital_Depart… ReferralType
<date> <chr> <dbl> <chr> <chr>
1 2015-08-01 AMNCH 1049 Paediatric ENT General Ref…
2 2015-08-01 AMNCH 1049 Paediatric Gast… General Ref…
3 2015-08-01 AMNCH 1049 Paediatric Gene… General Ref…
4 2015-08-01 Bantry Genera… 704 Gastroenterology General Ref…
5 2015-08-01 Bantry Genera… 704 General Medicine General Ref…
6 2015-08-01 Bantry Genera… 704 General Surgery General Ref…
7 2015-08-01 Bantry Genera… 704 Medicine for th… General Ref…
8 2015-08-01 Bantry Genera… 704 Outreach Dermat… General Ref…
9 2015-08-01 Bantry Genera… 704 Outreach Orthop… General Ref…
10 2015-08-01 Bantry Genera… 704 Outreach Surgic… General Ref…
# … with 12,268 more rows, and 1 more variable: TotalReferrals <dbl>파일명 컬럼 추가하기
데이터를 사용하다보면 보고 있는 값이 어느 파일에서 나온 것인지
확인하고 싶을 떄가 있습니다(역자주: 지금의 구조에서는 년도로 구분되어
있기 때문에 날짜 컬럼을 확인하면 됩니다만, .id 인자는
bind_rows() 함수에서도 유용하게 사용하는 것이니 알아두면
좋습니다.). map_dfr() 함수의 .id 인자를
지정하고 싶은 컬럼명(지금은 source)을 작성하는 것으로
사용하면, source 컬럼이 해당 파일이름이 추가되어 최종
데이터셋에 반영됩니다.
csv_files %>%
map_dfr(read_csv, .id = "source") %>%
mutate(Month_Year = myd(Month_Year, truncated = 1))
# A tibble: 12,278 × 7
source Month_Year Hospital_Name Hospital_ID Hospital_Depart…
<chr> <date> <chr> <dbl> <chr>
1 ie-general-r… 2015-08-01 AMNCH 1049 Paediatric ENT
2 ie-general-r… 2015-08-01 AMNCH 1049 Paediatric Gast…
3 ie-general-r… 2015-08-01 AMNCH 1049 Paediatric Gene…
4 ie-general-r… 2015-08-01 Bantry Gener… 704 Gastroenterology
5 ie-general-r… 2015-08-01 Bantry Gener… 704 General Medicine
6 ie-general-r… 2015-08-01 Bantry Gener… 704 General Surgery
7 ie-general-r… 2015-08-01 Bantry Gener… 704 Medicine for th…
8 ie-general-r… 2015-08-01 Bantry Gener… 704 Outreach Dermat…
9 ie-general-r… 2015-08-01 Bantry Gener… 704 Outreach Orthop…
10 ie-general-r… 2015-08-01 Bantry Gener… 704 Outreach Surgic…
# … with 12,268 more rows, and 2 more variables: ReferralType <chr>,
# TotalReferrals <dbl>마무리
본 포스트는 fs 패키지, purrr 패키지,
readr 패키지를 활용해서 폴더 내의 파일들 리스트를 가져와서
tidyverse 패키지의 도구들도 분석하기 좋은 상태인 하나의
data.frame으로 불러오는 작은 예제를 제공한다.
한번에 동작하는 코드 전체는 아래와 같다.
data_dir %>%
dir_ls(regexp = "\\.csv$") %>%
map_dfr(read_csv, .id = "source") %>%
mutate(Month_Year = myd(Month_Year, truncated = 1))dir_ls() 함수로 data_dir 폴더내의 파일 리스트를
가져와서, read_csv() 함수를 map_dfr() 함수와
함께 리스트의 파일들을 한번에 불러옵니다. .id 인자로
source 컬럼을 추가하여 어느 파일에서 나온 데이터인지 최종
데이터셋에서 확인할 수 있습니다. 이제 dplyr 패키지로
데이터를 처리 할 준비가 되었습니다.
코드는 조금만 바꿔서 SAS 파일이나 Excel 파일 같은 다른 파일 형식을
위한 형태로 고칠 수 있습니다. read_csv() 함수를
haven::read_sas()나 readxl::read_xlsx()로
바꾸고 regexp 인자를 해당 확장자명으로 고치는 것입니다.
In future posts, we’ll also look at other ways we merge a folder of
data files besides “stapling” them together row-wise with map_dfr().
(역자주: stapling이 어떤 의미인지 이해하지 못해서 마지막
문장은 원문으로 두었습니다.)
역자 의견
purrr 패키지는 저도 아직
이해를 잘 못하고 있지만, 제대로 쓰기를 기대하는 패키지 중 하나 입니다.
R이 for문의 성능이 떨어지기 때문에 apply계열 함수를 잘 사용해야 한다는
이야기들을 하지만, 모던 R 프로그래밍에서는 purrr 패키지의
map_*() 계열 함수를 잘 사용해야 하는 것 같습니다.
KRUG에서
언뜻 map()으로 어떤 처리코드보다도 빠르게 동작하는 코드를
공유해주신 분을 기억합니다. 덕분에 관심만 두고 있었는데, 빨리 더
살펴봐야 겠네요.
글의 내용과는 무관하게 본 포스트는 총 4줄의 코드를 설명하고 있습니다. 반성을 많이 하게 되네요.